зҫҪжҜӣзҗғдҪңдёәдёҖйЎ№ж·ұеҸ—ж¬ўиҝҺзҡ„иҝҗеҠЁпјҢе°Өе…¶еңЁе№ҝе·һжӢҘжңүдј—еӨҡзҡ„зҲұеҘҪиҖ…е’Ңдё“дёҡйҳҹдјҚгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®Ёе№ҝе·һзҫҪжҜӣзҗғйҳҹзҡ„жҜ”иөӣжҠҖе·§дёҺз»ҸйӘҢеҲҶдә«пјҢд»ҺеӣӣдёӘж–№йқўиҜҰз»Ҷи§ЈжһҗиҜҘйҳҹзҡ„и®ӯз»ғж–№жі•гҖҒжҲҳжңҜзҗҶеҝөгҖҒеҝғзҗҶзҙ иҙЁд»ҘеҸҠеӣўйҳҹеҚҸдҪңзӯүеҶ…е®№гҖӮйҖҡиҝҮиҝҷдәӣеҶ…е®№пјҢиҜ»иҖ…дёҚд»…еҸҜд»ҘдәҶи§ЈеҰӮдҪ•жҸҗеҚҮиҮӘиә«зҡ„зҫҪжҜӣзҗғж°ҙе№іпјҢиҝҳиғҪж„ҹеҸ—еҲ°е№ҝе·һзҫҪжҜӣзҗғйҳҹеңЁиҝҷйЎ№иҝҗеҠЁдёӯзҡ„зӢ¬зү№йӯ…еҠӣдёҺйЈҺйҮҮгҖӮжҜҸдёҖдёӘз»ҶиҠӮйғҪе°Ҷдёәе№ҝеӨ§зҫҪжҜӣзҗғзҲұеҘҪиҖ…жҸҗдҫӣе®һз”Ёзҡ„жҢҮеҜјпјҢеҠ©еҠӣ他们еңЁжҜ”иөӣдёӯеҸ–еҫ—жӣҙеҘҪзҡ„жҲҗз»©гҖӮ
1гҖҒи®ӯз»ғж–№жі•дёҺжҠҖе·§
е№ҝе·һзҫҪжҜӣзҗғйҳҹжіЁйҮҚзі»з»ҹеҢ–зҡ„и®ӯз»ғж–№жі•пјҢд»Ҙ科еӯҰгҖҒй«ҳж•ҲдёәеҺҹеҲҷгҖӮеңЁж—Ҙеёёи®ӯз»ғдёӯпјҢ他们дјҡж №жҚ®дёҚеҗҢзҗғе‘ҳзҡ„зү№зӮ№еҲ¶е®ҡдёӘжҖ§еҢ–зҡ„и®ӯз»ғи®ЎеҲ’гҖӮдҫӢеҰӮпјҢеҜ№дәҺжҠҖжңҜеҹәзЎҖиҫғејұзҡ„йҖүжүӢпјҢдјҡе®үжҺ’жӣҙеӨҡзҡ„еҹәзЎҖжҠҖиғҪз»ғд№ пјҢеҰӮеҸ‘зҗғгҖҒжҺҘеҸ‘зҗғзӯүпјӣиҖҢеҜ№дәҺжҠҖжңҜиҫғдёәжҲҗзҶҹзҡ„йҖүжүӢпјҢеҲҷдјҡдҫ§йҮҚдәҺжҲҳжңҜй…ҚеҗҲдёҺз»јеҗҲзҙ иҙЁжҸҗеҚҮгҖӮ
жӯӨеӨ–пјҢиҜҘйҳҹиҝҳзү№еҲ«ејәи°ғдҪ“иғҪи®ӯз»ғзҡ„йҮҚиҰҒжҖ§гҖӮзҫҪжҜӣзҗғжҳҜдёҖйЎ№еҜ№иә«дҪ“зҙ иҙЁиҰҒжұӮжһҒй«ҳзҡ„иҝҗеҠЁпјҢеӣ жӯӨпјҢйҳҹе‘ҳ们еңЁж—Ҙеёёи®ӯз»ғдёӯйғҪдјҡиҝӣиЎҢдё“йЎ№дҪ“иғҪй”»зӮјпјҢеҢ…жӢ¬еҠӣйҮҸгҖҒйҖҹеәҰе’ҢиҖҗеҠӣзӯүж–№йқўпјҢд»ҘжҸҗй«ҳж•ҙдҪ“з«һжҠҖж°ҙе№ігҖӮ
жңҖеҗҺпјҢжҠҖжңҜеҲҶжһҗд№ҹжҳҜ他们и®ӯз»ғзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶгҖӮж•ҷз»ғеӣўйҳҹдјҡеҲ©з”Ёи§Ҷйў‘еӣһж”ҫе’Ңж•°жҚ®еҲҶжһҗпјҢеҜ№жҜҸдҪҚйҖүжүӢеңЁжҜ”иөӣдёӯзҡ„иЎЁзҺ°иҝӣиЎҢиҜҰз»Ҷеү–жһҗпјҢеё®еҠ©д»–们еҸ‘зҺ°дёҚ足并еҠ д»Ҙж”№иҝӣгҖӮиҝҷз§ҚеҸҚйҰҲжңәеҲ¶еӨ§еӨ§жҸҗеҚҮдәҶйҳҹе‘ҳ们еҜ№иҮӘиә«жҠҖиғҪж°ҙе№ізҡ„и®ӨзҹҘе’Ңи°ғж•ҙиғҪеҠӣгҖӮ
2гҖҒжҲҳжңҜзҗҶеҝөдёҺеә”з”Ё
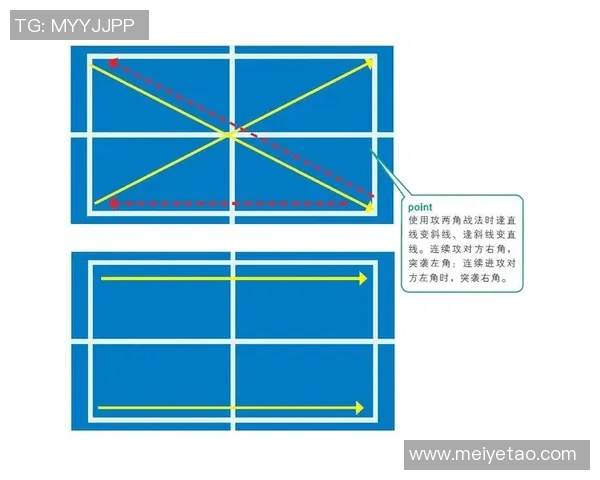
е№ҝе·һзҫҪжҜӣзҗғйҳҹеңЁжҲҳжңҜиҝҗз”ЁдёҠйқһеёёзҒөжҙ»пјҢж №жҚ®еҜ№жүӢзү№зӮ№е’ҢжҜ”иөӣжғ…еҶөеҸҠж—¶и°ғж•ҙзӯ–з•ҘгҖӮ他们йҖҡеёёйҮҮз”ЁвҖңж”»йҳІз»“еҗҲвҖқзҡ„жҲҳжңҜпјҢйҖҡиҝҮеҝ«йҖҹжңүж•Ҳең°жҺ§еҲ¶еңәдёҠиҠӮеҘҸжқҘеҺӢеҲ¶еҜ№жүӢгҖӮдҫӢеҰӮпјҢеңЁйқўеҜ№ж”»еҮ»еһӢйҖүжүӢж—¶пјҢ他们еҫҖеҫҖйҖүжӢ©зЁіжүҺзЁіжү“пјҢд»ҘйҳІе®ҲеҸҚеҮ»дёәдё»пјҢжҸҗй«ҳиғңеҲ©жңәдјҡгҖӮ
еҗҢж—¶пјҢиҜҘйҳҹд№ҹжіЁйҮҚжҗӯй…ҚдёҚеҗҢйЈҺж јзҡ„йҖүжүӢпјҢд»ҘеҪўжҲҗжңҖдҪіз»„еҗҲгҖӮеңЁеҸҢжү“иөӣдәӢдёӯпјҢеҗҲзҗҶеҲҶе·ҘдёҺй»ҳеҘ‘й…ҚеҗҲжҳҜеҸ–иғңе…ій”®гҖӮеӣ жӯӨпјҢ他们дјҡйҖҡиҝҮеӨ§йҮҸе®һжҲҳжј”з»ғеҹ№е…»йҳҹе‘ҳд№Ӣй—ҙзӣёдә’дҝЎд»»е’ҢзҗҶи§ЈпјҢдҪҝеҫ—жҜҸеҗҚйҖүжүӢиғҪеӨҹе……еҲҶеҸ‘жҢҘиҮӘе·ұзҡ„дјҳеҠҝгҖӮ
йҷӨдәҶдј з»ҹжҲҳжңҜеӨ–пјҢе№ҝе·һзҫҪжҜӣзҗғйҳҹиҝҳз§ҜжһҒе°қиҜ•еҲӣж–°жү“жі•пјҢдҫӢеҰӮйҮҮз”ЁеҸҳйҖҹзӘҒиўӯзӯүж–°йў–ж–№ејҸжқҘжү“д№ұеҜ№ж–№иҠӮеҘҸгҖӮиҝҷдәӣеҲӣж–°дёҚд»…дҪҝеҫ—他们еңЁжҜ”иөӣдёӯжӣҙе…·еЁҒиғҒжҖ§пјҢд№ҹеҗёеј•дәҶи§Ӯдј—жіЁж„ҸпјҢдёәжҜ”иөӣеўһж·»дәҶдёҚе°‘и§ӮиөҸжҖ§гҖӮ
3гҖҒеҝғзҗҶзҙ иҙЁеҹ№е…»
дјҳз§Җзҡ„еҝғзҗҶзҙ иҙЁжҳҜдҪ“иӮІз«һжҠҖжҲҗеҠҹдёҚеҸҜжҲ–зјәзҡ„дёҖйғЁеҲҶгҖӮе№ҝе·һзҫҪжҜӣзҗғйҳҹеҚҒеҲҶйҮҚи§ҶиҝҷдёҖзӮ№пјҢз»ҸеёёйӮҖиҜ·еҝғзҗҶ专家иҝӣиЎҢи®Іеә§е’Ңиҫ…еҜјпјҢдҪҝйҳҹе‘ҳ们иғҪеӨҹеӯҰдјҡи°ғиҠӮжғ…з»ӘгҖҒеә”еҜ№еҺӢеҠӣпјҢжҸҗй«ҳиҮӘдҝЎеҝғгҖӮеҗҢж—¶пјҢ他们д№ҹйј“еҠұйҳҹе‘ҳеҲҶдә«дёӘдәәз»ҸеҺҶпјҢд»ҺиҖҢе»әз«Ӣиө·иүҜеҘҪзҡ„еӣўйҳҹж°ӣеӣҙгҖӮ
дёәдәҶеўһејәжҠ—еҺӢиғҪеҠӣпјҢиҜҘйҳҹиҝҳи®ҫзҪ®дәҶдёҖдәӣжЁЎжӢҹжҜ”иөӣзҺҜиҠӮпјҢи®©йҖүжүӢ们еңЁжҺҘиҝ‘зңҹе®һжҜ”иөӣзҺҜеўғдёӢиҝӣиЎҢй”»зӮјпјҢиҝҷз§ҚвҖңиөӣеүҚеҺӢеҠӣжөӢиҜ•вҖқжңүеҠ©дәҺ他们дјҹеҫ·еӣҪйҷ…1946йҖӮеә”еҗ„з§Қжғ…еўғпјҢ并еӯҰдјҡеҶ·йқҷеӨ„зҗҶзӘҒеҸ‘зҠ¶еҶөгҖӮжӯӨеӨ–пјҢйҖҡиҝҮдёҚж–ӯз§ҜзҙҜе®һжҲҳз»ҸйӘҢпјҢйҖүжүӢ们йҖҗжёҗеҪўжҲҗдәҶиҮӘе·ұзҡ„еҝғзҗҶи°ғйҖӮжңәеҲ¶пјҢжңүж•Ҳзј“и§Јзҙ§еј жғ…з»ӘгҖӮ

жңҖеҗҺпјҢжӯЈйқўжҖқз»ҙд№ҹжҳҜйҮҚиҰҒдёҖзҺҜгҖӮеңЁж—ҘеёёдәӨжөҒдёӯпјҢж•ҷз»ғеҸҠиҖҒе°Ҷ们дјҡйҖҡиҝҮжҝҖеҠұжҖ§зҡ„иҜӯиЁҖйј“иҲһе№ҙиҪ»йҳҹе‘ҳпјҢдҪҝе…¶дҝқжҢҒз§ҜжһҒеҗ‘дёҠзҡ„жҖҒеәҰпјҢд»ҺиҖҢжҸҗеҚҮж•ҙдҪ“еӣўйҳҹеЈ«ж°”гҖӮиҝҷз§ҚзІҫзҘһеҠӣйҮҸж— з–‘жҲҗдёә他们еҸ–еҫ—дјҳејӮжҲҗз»©зҡ„йҮҚиҰҒдҝқйҡңгҖӮ
4гҖҒеӣўйҳҹеҚҸдҪңдёҺжІҹйҖҡ
еӣўйҳҹеҚҸдҪңжҳҜд»»дҪ•йӣҶдҪ“йЎ№зӣ®жҲҗеҠҹзҡ„йҮҚиҰҒеӣ зҙ пјҢиҖҢе№ҝе·һзҫҪжҜӣзҗғйҳҹеҜ№жӯӨж·ұжңүдҪ“дјҡгҖӮеңЁе№іж—¶и®ӯз»ғдёӯпјҢ他们ејәи°ғзӣёдә’й—ҙзҡ„дҝЎжҒҜжІҹйҖҡпјҢйҖҡиҝҮи®Ёи®әеҲ¶е®ҡе…ұеҗҢзӣ®ж ҮпјҢд»ҘеўһејәйӣҶдҪ“иҚЈиӘүж„ҹгҖӮеҗҢж—¶пјҢжҜҸж¬Ўи®ӯз»ғз»“жқҹеҗҺйғҪдјҡз»„з»ҮжҖ»з»“дјҡи®®пјҢи®©жҜҸдҪҚжҲҗе‘ҳйғҪжңүжңәдјҡеҲҶдә«иҮӘе·ұзҡ„зңӢжі•е’Ңе»әи®®пјҢиҝҷз§Қдә’еҠЁдҪҝеҫ—еӣўйҳҹж°ӣеӣҙжӣҙеҠ иһҚжҙҪгҖӮ
еңЁеҸҢжү“жҲ–еӣўдҪ“иөӣдёӯпјҢжӣҙеҠ йңҖиҰҒй»ҳеҘ‘й…ҚеҗҲгҖӮеӣ жӯӨпјҢ他们з»ҸеёёејҖеұ•дёҖдәӣеӣўе»әжҙ»еҠЁпјҢдёҚд»…еҠ ејәеҪјжӯӨд№Ӣй—ҙдәҶи§ЈпјҢд№ҹдҝғиҝӣеҗҲдҪңж„ҸиҜҶгҖӮдҫӢеҰӮпјҢйҖҡиҝҮи¶Је‘іжёёжҲҸжӢүиҝ‘и·қзҰ»пјҢи®©йҳҹе‘ҳ们еңЁиҪ»жқҫж„үеҝ«зҡ„ж°ӣеӣҙдёӢеўһиҝӣж„ҹжғ…пјҢдёәжңӘжқҘжӯЈејҸжҜ”иөӣеҘ е®ҡиүҜеҘҪеҹәзЎҖгҖӮ
еҸҰеӨ–пјҢиҜҘйҳҹиҝҳжіЁйҮҚеҹ№е…»е№ҙиҪ»дәәжӢ…д»»йўҶиў–и§’иүІпјҢи®©е…¶иҙҹиҙЈе°Ҹз»„еҶ…еҚҸи°ғе·ҘдҪңпјҢиҝҷж ·ж—ўиғҪй”»зӮје№ҙиҪ»дәәзҡ„йўҶеҜјжүҚиғҪпјҢд№ҹи®©ж•ҙдёӘеӣўйҳҹжңқзқҖз»ҹдёҖж–№еҗ‘еҸ‘еұ•гҖӮиҖҢиҝҷз§Қдј жүҝејҸзҡ„еҸ‘еұ•жЁЎејҸпјҢдҪҝеҫ—е№ҝе·һзҫҪжҜӣзҗғйҳҹе§Ӣз»ҲдҝқжҢҒз«һдәүеҠӣе’Ңжҙ»еҠӣгҖӮ
жҖ»з»“пјҡ
йҖҡиҝҮд»ҘдёҠеҮ дёӘж–№йқўпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°е№ҝе·һзҫҪжҜӣзҗғйҳҹдёҚи®әжҳҜеңЁжҠҖжңҜеұӮйқўиҝҳжҳҜеҝғзҗҶеұӮйқўпјҢйғҪеұ•зҺ°еҮәдәҶдёҖж”Ҝй«ҳж°ҙе№іиҒҢдёҡзҗғйҳҹеә”жңүзҡ„йЈҺиҢғгҖӮ他们дёҘи°Ёз»ҶиҮҙең°еҲ¶е®ҡи®ӯз»ғи®ЎеҲ’пјҢд»ҘеҸҠзҒөжҙ»еӨҡеҸҳзҡ„жҲҳжңҜеә”з”ЁпјҢж— з–‘дёәе…¶д»–йҳҹдјҚж ‘з«ӢдәҶжҰңж ·гҖӮеҗҢж—¶пјҢеңЁеҝғзҗҶзҙ иҙЁе’ҢеӣўйҳҹеҚҸдҪңж–№йқўжүҖеҒҡеҮәзҡ„еҠӘеҠӣпјҢжӣҙжҳҜи®©иҝҷж”Ҝзҗғйҳҹе……ж»ЎеҮқиҒҡеҠӣдёҺеҗ‘еҝғеҠӣпјҢдёәе…¶дёҚж–ӯиҝҪжұӮеҚ“и¶ҠжҸҗдҫӣдәҶејәеӨ§еҠЁеҠӣгҖӮ
Total takeaways highlight the importance of a comprehensive training regimen that encompasses physical, technical, psychological, and team dynamics. еҸӘжңүе…ЁйқўжҸҗеҚҮеҗ„дёӘж–№йқўпјҢиҝҷж”ҜеҶ еҶӣд№ӢеёҲжүҚиғҪеӨҹ继з»ӯеңЁеӣҪеҶ…еӨ–иөӣдәӢдёӯеҲӣйҖ дҪіз»©пјҢе°Ҷе№ҝе·һеёӮж°‘зғӯзҲұзҡ„иҝҷйЎ№иҝҗеҠЁжҺЁеҗ‘ж–°зҡ„й«ҳеәҰпјҒ